더 스마트한 예측을 위한 콘텍스트 기반 LLM 예측 모델
글 / 벡스 심슨(Becks Simpson), 마우저 일렉트로닉스(Mouser Electronics)

(출처: decorator/stock.adobe.com; AI로 생성)
대부분의 예측 모델은 목표 시계열 데이터만을 가지고 학습된 통계 모델이나 딥러닝 모델이다. 이런 접근 방식은 미래의 데이터가 과거 데이터와 비슷하게 나타날 것으로 예상될 때는 잘 작동한다. 그러나 신호가 외부 요인에 의해 결정되거나, 판촉 행사·날씨·장애·정책 변화처럼 과거 데이터에 미친 영향을 설명해야 하는 이상치가 포함된 경우에는 성능이 떨어진다. 예를 들어 소매 판매는 판촉 행사 기간 동안 급증하고, 에너지 수요는 기온과 공휴일에 따라 달라지며, 운영 지표는 계획된 조치에 따라 변화한다. 단순히 숫자만 학습하는 모델은 이런 실제 세계의 변화 요인들을 놓치게 된다.
고도화된 추론 능력을 가진 대규모 언어 모델(LLM)은 이러한 워크플로우를 바꿀 수 있다. 수치 데이터와 간결한 도메인 설명을 함께 제공하면, LLM은 실제 콘텍스트를 통합해 예측을 생성하고 그 배경 요인들까지 설명할 수 있다. 이 글에서는 순수 시계열 기법이 어려움을 겪는 상황, 콘텍스트 기반 LLM 예측 모델이 작동하는 방식, 추가로 제공해야 할 콘텍스트 정보, 그리고 실제 적용 시의 장점과 한계를 살펴본다.
순수 시계열 예측 모델의 한계
시계열 예측 모델은 데이터가 충분하고, 과거가 미래의 모습을 대부분 담고 있을 때 좋은 성과를 낸다. 그러나 이러한 모델은 숫자만을 가지고 계절성이나 추세 같은 패턴을 암묵적으로 학습하기 때문에, 중요한 요인이 시계열 외부에 있을 경우에는 예측이 어려워진다. 이런 상황은 가용한 데이터의 기간이 짧거나, 예측에 영향을 줄 미래 사건이 예정되어 있거나, 과거의 특정 활동으로 인해 이상치처럼 보이는 값이 생성되었지만 단순한 이상치로 처리할 수 없는 경우 등 여러 이유로 인해 발생할 수 있다. 이런 경우, 모델은 데이터에서 이 시계열을 예측하는 ‘규칙성’을 찾아내려 하지만, 실제로는 그 규칙성을 제대로 파악할 수 없다.
데이터가 충분하지 않으면 모델은 특정 데이터 포인트에 얼마나 가중치를 두어야 할지 판단할 수 없다. 예를 들어, 연중 중간 시점과 연말의 데이터가 매우 중요하더라도 한 해의 월별 데이터만 제공된다면 모델은 이 사실을 이해할 수 없다. 마찬가지로, 새로운 마케팅 캠페인이나 판촉 이벤트가 매출을 몇 퍼센트 끌어올리는 것으로 알려져 있거나, 특정 장애 발생으로 인해 향후 수치가 감소할 것이 분명한 경우에도, 시계열 데이터만을 학습하는 모델은 이런 요인을 반영할 수 없다.
고전적인 예측 모델의 또 다른 한계는 블랙박스 특성이다. 즉, 모델이 주어진 데이터로 어떻게 결정을 내렸는지, 특정 예측이 어떤 근거를 기반으로 하고 있는지 명확하게 알기 어렵다. 사용자가 특정 예측이 만들어진 이유를 알고 싶어도 그 근거를 확인할 수 없다면, 모델이 산출한 결과에 대한 신뢰도는 쉽게 흔들릴 수 있다.
LLM 예측에서 핵심은 ‘콘텍스트’
예측의 정확도를 높이기 위해서는 도메인 지식을 반영할 수 있어야 하며, 이를 위해 개발자는 LLM을 활용해 과거 데이터와 함께 콘텍스트 정보를 포함한 예측을 생성할 수 있다. 이러한 방식은 먼저 적합한 LLM을 선택하고, 기본적인 프롬프트 템플릿을 만든 다음, 해당 예측 작업에 필요한 과거 데이터와 구체적인 콘텍스트 정보를 함께 입력하는 절차로 진행된다. 전문가(SME)가 하듯이, 예측 과정은 데이터를 검토하고, 도메인 지식이 데이터의 움직임에 어떤 영향을 줄지 파악한 뒤, 이 둘을 결합해 미래 값을 추정하는 여러 논리적 단계로 이루어진다. 이런 행동 방식을 잘 모방하는 모델이 추론 능력이 뛰어난 모델로서 Gemini Pro 2.5, GPT o4-mini, GPT-o3 같은 모델이 대표적이다. 이들 모델은 보통 일련의 사고 과정을 거쳐 문제를 단계적으로 해결한다. 또한 Llama-3.1-405B-Inst처럼 다양한 콘텍스트에서도 높은 성능을 내는 고급 LLM도 좋은 선택이 될 수 있다.
수치 데이터와 함께 제공할 수 있는 콘텍스트 정보에는 값의 제한이나, 사용 가능한 데이터 기간보다 더 긴 주기를 가진 계절성과 같은 ‘비시계적(intemporal)’ 정보가 포함될 수 있다. 시계열 데이터만으로는 알 수 없는 과거의 사실들도 반드시 포함해야 한다. 예를 들어 센서 유지보수로 인해 측정값이 일시적으로 떨어졌거나 작업 중단으로 물량이 줄어든 경우라면, 이는 실제 추세가 아니라는 표시를 해두어야 한다. 비슷한 사건이 다시 일어날 것이 아니라면 모델이 이런 변동을 잘못된 근거로 삼아 예측을 왜곡하지 않도록 하기 위함이다. 또한 인과적 정보도 함께 제공해야 한다. 개입이 일어난 시점과 예상되는 영향 규모, 또는 과거에 관측된 효과값 등이 여기에 해당한다. 예를 들어 “10월에 캠페인 A가 시작되며, 보통 2주 동안 주문량을 8~12% 증가시킨다”와 같은 정보는 단순한 패턴 매칭을 넘어 예측을 더 정교하게 만드는 실질적인 근거가 될 수 있다.
간단한 콘텍스트 기반 프롬프트 구조는 다음과 같다.
• 시계열과 예측하려는 기간을 설명한다.
• 날짜와 값 형태로 과거 데이터를 나열하고, 필요한 경우 추가적인 수치 데이터를 함께 제공한다(그림 1).
• 예측 규칙을 이해하는 데 필요한 모든 관련 콘텍스트를 추가한다. 이는 데이터에는 드러나지 않지만 예측에 영향을 미치는 정보를 포함한다.
• 출력 형식을 어떻게 해야 하는지, 그리고 그 결과가 상위 프로세스에서 사용되어야 하는지 등을 설명한다(그림 2).
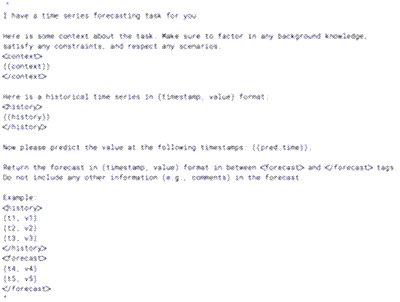
그림 1. 콘텍스트 기반 LLM 예측을 위한 템플릿 프롬프트 예시 (출처: 저자)

그림 2. 관련 콘텍스트와 과거 데이터가 채워진 템플릿 예시 (출처: 저자)
이런 콘텍스트 기반 모델 구조에서는, 모델이 수치 기반의 과거 기록과 제공된 요약 정보를 함께 해석해 예측 결과와 그에 대한 근거를 제시하는 역할을 하게 된다.
콘텍스트 인지형 LLM 예측의 현실
콘텍스트를 반영하는 LLM 기반 예측 모델은 규칙을 명확히 기술할 수 있고, 외부 요인이 잘 알려진 도메인에서 특히 강점을 보인다. 예를 들어 판촉 일정이 있는 소매 분야, 날씨 예보와 공휴일이 중요한 에너지 분야, 계획된 정비나 정전이 있는 운영 분야 등이 이에 해당한다. 또한 해석 가능성이 필요할 때 매우 매력적인 접근 방식이며, 추론 중심 모델은 자연스러운 문장 형태로 예측의 근거를 제시할 수 있다.
단점도 존재한다. 연구 결과에 따르면 이러한 모델은 때때로 다른 모델보다 더 크게 오류를 발생할 수 있으며, 실제 값보다 500%까지[1] 과소 또는 과대 예측하는 경우도 있다. 여기에 비용과 지연 시간도 고려해야 한다. 모델의 규모가 클수록 일반적으로 더 나은 추론 능력을 보이지만, 그만큼 토큰 사용량이 많아질 수밖에 없다. 따라서 예측 정확도와 해석 가능성을 충족하면서도 가능한 작은 모델을 선택하는 것이 중요하다. 또한 전통적 시계열 예측 방법과 LLM 기반 예측을 함께 사용하는 앙상블 기법을 적용하면 오류의 영향을 줄이는 데 도움이 될 수 있다.
맺음말
순수 시계열 모델은 패턴을 효율적으로 학습하지만, 미래가 명확한 외부 요인에 의해 결정되는 경우에는 성능이 떨어진다. 콘텍스트를 반영한 LLM 기반 예측은 규칙, 제약 조건, 날짜가 있는 개입 정보를 함께 반영해 수치 기반 기록과 정합성을 맞추며, 예측값과 그에 대한 타당한 근거를 제시함으로써 이 한계를 보완한다. 이 방식은 명확한 인과 관계 설명과 관련성 높은 배경 정보가 간결하게 제공될 때, 그리고 예측 과정의 해석 가능성이 중요한 요구사항일 때 가장 효과적이다.
이러한 모델은 순수한 수치 데이터만으로 학습된 모델보다 훨씬 높은 정확도를 보일 수 있지만, 반대로 더 크게 실패할 가능성도 존재한다. 따라서 정확한 수치 예측 모델과 잘 브리핑된 추론 모델을 함께 사용해 더 스마트하고 신뢰하기 쉬운 예측을 만들어내는 것이 바람직하다.
출처
https://arxiv.org/pdf/2410.18959
저자 소개

벡스 심슨(Becks Simpson)은 개발자, 제품 디자이너, ML 전문가들이 함께 힘을 합쳐 상상 속의 AI 제품을 현실로 만드는 앨리콥 노르드(AlleyCorp Nord)의 머신 러닝 책임자다. 새로운 딥 러닝 기법을 검토하고 연구를 실제 문제 해결에 적용하는 것에서부터 AI 모델을 학습 및 구축하기 위한 파이프라인과 플랫폼을 설계하고 스타트업들에게 AI와 데이터 전략에 관한 자문을 제공하는 등의 일을 한다.